Sponsored
Roundtable: How to harness AI
In association with
Published 5 July 2019
This is the Sponsored paywall logged out

Utilities keen to become data-driven enterprises need to put in the hard work up front. Jane Gray reports from a roundtable discussion on the foundations necessary for exploiting artificial intelligence.
Artificial intelligence, or AI, now features strongly in any utility industry conversation about the technologies that will underpin future business and operating models. It is said to offer opportunities to transform customer service and operations by unlocking data insights that human endeavour might never discover – or at any rate might take aeons in the attempt.
That is a tantalising prospect for utilities companies under the cosh – due to market forces and regulatory pressure – to realise ever greater efficiencies and to innovate for enhanced customer value. Attendees at a recent roundtable discussion in London, hosted by Utility Week in association with Cambridge Technology, were keen to grasp this potential and engaged in a lively debate and exchange of experience, which generated a range of key lessons about the actions it is necessary to take in order to get the most out of AI. Here, we present a few of them.
Govern your data
To be able to reliably generate insight and actions from AI applications, significant groundwork needs to be done to organise available data and put a data governance structure in place. Some of the organisations represented at the roundtable were significantly further ahead with this process than others. The more advanced among the group had already invested years of work in creating structures to ensure the right people in their organisations had access to the right information for AI experimentation – and that this information is held within an appropriate architecture that supports visibility and co-ordination of developing AI use cases.
Commonly, this work has included creating platforms that are “decoupled” or “loosely coupled” to the core business to allow for experimentation with algorithms. Some companies have also begun building “data lakes” (as opposed to traditional data warehouses), which can pool a wide variety of structured and unstructured data from within the organisation and relevant external sources.
With such structures in place, a key next-step challenge for optimising AI outputs was identified in finding ways to “publish” useful algorithms back to the business in a way that is trusted and facilitates uptake in business as usual.
Don’t underestimate AI training needs
The need to train AI is often hugely underestimated. To create a reliable and useful “digital person” – as one participant described AI programs – a large quantity of high quality data and significant human “teaching” time is required to establish smooth-running “neural networks”. Gathering and preparing suitable data for running training programmes can be challenging. For some AI use cases, suitable data sets may not yet even exist or be accessible to utilities.
In the future, advanced machine learning capability will be able to expedite this task but, for now, such AI maturity remains the domain of technology blue chips.
Align with strategic objectives
AI value will always remain limited unless it can be linked directly to an organisational vision and strategy, attendees agreed. This remains a key challenge for most utilities where even the most advanced could be predominantly defined as having an “initiative-based” approach to using the technology.
A key challenge, therefore, for almost all utilities is to establish an enterprise data model that is specifically designed to support key strategic objectives. For some water companies at our roundtable, the approach of the next asset management plan period, AMP7, has been leveraged as a driver for this next stage of data maturity, and collaboration is under way with enterprise architecture teams to ensure data lake information is able to “talk” to core business systems.
AI for a better smart meter rollout
A wide range of use cases for AI were discussed over the course of this roundtable discussion. The most prominent included supporting the smart meter rollout, leakage detection and identifying vulnerable customers.
With regards to supporting effective smart meter deployment, one participant described an interesting use case for AI in identifying problematic installation sites – the idea being to avoid sending engineers to any site where it appears uncertain that an installation can be completed. This would reduce the company’s exposure to the significant costs associated with failed installations and minimise wasted customer time, thereby also driving better customer satisfaction with the smart meter rollout.
The AI program in development will use photographs of customer meter locations in order to identify barriers to a successful smart meter install – such as partial or complete obscuring of the meter, a lack of space for new meter installation and potentially other problems like the presence of asbestos.
Customers booking an appointment for a smart meter installation would be asked to provide a photograph of the current meter (which could be taken on a smartphone ). This photograph would be automatically processed by the AI program, which would raise the alarm about any problems and the customer would be informed if there was a need to postpone or cancel the installation appointment.
Data lakes versus data warehouses
The first and crucial foundational step towards the creation of a data-driven utility is to develop a plan for collecting, managing and exploiting existing data within the enterprise into what is often called a “data lake.”
The graphic below identifies one of the critical problems with the classical data warehouse approaches, especially as it relates to the taking full advantage of data-driven AI and machine learning opportunities.
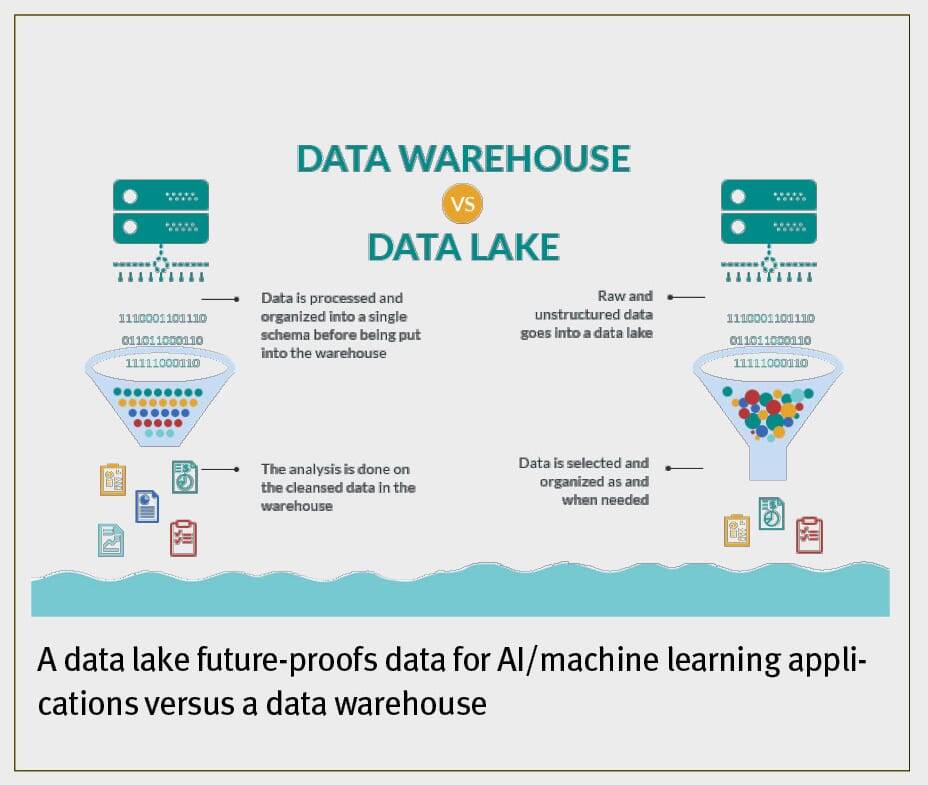
Typically they require that data be organised, normalised (often resulting in some kinds of data loss) and put into predefined schemes before being stored in the data warehouse. This is an efficient and reasonable approach, however, only in a world where (a) the kinds and characteristics of the data coming in are well known, and (b) all of the potential uses for which the data is to be used is known and understood beforehand.
However, when data-driven AI or machine learning applications become critical drivers of value, it is of paramount importance to have highly efficient, flexible ways of storing large amounts of multi-modal data in the original unprocessed format. With this kind of architecture, maximum flexibility is maintained for defining new types of data selection and pre-processing that will be necessary as new uses and applications for the data are discovered and developed.
For a utility, the data lake should begin by ingesting various kinds of existing historical information and prioritising those collections of data that are likely, when analysed with machine learning algorithms, to make predictions tied to achieving specific and agreed upon business objectives.
Initially, these kinds of data can be existing data, to develop applications like the predictive analytics for maintenance of assets that we describe first below. But ultimately many different multi-modal types of data could go into the data lake, from customer-centric sentiment data like Twitter data, to high-frequency time series data like voltage levels from transmission lines, to high-density image data from satellite images, drones, and Lidar.
Please login or Register to leave a comment.